How To Build Your SEO API Stack
Most enterprise SEO recommendations die in a backlog. Not because the insights are wrong, but because the data they're based on lives inside a suite that can't talk to the systems where work actually happens, think Jira, GitHub, Looker, Slack.
Your enterprise SEO software knows a page has a crawl issue. But your engineers won't find out until someone manually exports a spreadsheet and pastes it into a Jira ticket.
That's the operations gap. And the problem isn't a shortage of data but a shortage of connected data. SEO APIs close that gap. They turn SEO from a standalone reporting function into an operational data layer that connects directly into the systems enterprises already use.
This guide shows you the full plumbing: the API surface area, five production workflow pipelines, a reference architecture you can hand to a data engineer, and honest cost math against suite licensing.
Why Is Enterprise SEO Becoming an API Problem?
Enterprise SEO has become an API problem for various reasons. The SERP is changing too fast, BI tooling has consolidated around data warehouses, and programmatic publishers are tracking too many keywords for per-seat pricing to survive contact with a spreadsheet.
SEO APIs give technical teams direct, programmable access to the data layer, decoupled from any one vendor's UI, rate limits per user, or quarterly contract negotiation.
An SEO API is a programmatic interface that returns, exposes, or serves SEO data through structured endpoints and JSON responses.
Instead of accessing rankings, backlinks, keywords, crawl data, or visibility metrics through a UI alone, teams can pull that information directly into warehouses, ETL pipelines, dashboards, and automation systems.
Here is why enterprise SEO is becoming an API problem:
AI Overviews Are Fragmenting the SERP at Scale
Google’s AI Overviews and ongoing SGE-style SERP experimentation have fundamentally changed rank tracking.
Traditional enterprise rank tracking assumed a relatively stable SERP structure:
10 blue links
A few SERP features
Predictable ranking movement
That assumption no longer holds.
Today, rankings fluctuate based on, AI-generated summaries, dynamic citations, query intent interpretation, device-level SERP variations, geographic localization, and personalization layers
Monitoring those changes in real time requires high volume data collection frequency.
For instance, a team tracking 5,000 keywords weekly in 2022 may now need daily refreshes, multi-location tracking, AI Overview detection, SERP feature extraction, and mobile/desktop segmentation.
This is where per-seat enterprise SEO software pricing begins to break down. API-driven collection scales more predictably because teams only pay for consumption and storage rather than layered seat licensing.
BI Consolidation Means Every Team Already Has Looker or Tableau
Most enterprises already standardized around BI infrastructure years ago.
The modern analytics stack usually includes:
BigQuery or Snowflake
dbt transformations
Looker or Tableau dashboards
Fivetran or Airbyte ingestion
Slack alerts
Reverse ETL workflows
Executives do not want another isolated SEO dashboard.
They want:
Organic visibility blended with pipeline attribution
SEO trends joined with CRM data
Share of voice integrated into executive reporting
Forecasting inside existing dashboards
That creates pressure for SEO data to behave like every other enterprise data source.
APIs let you pipe SERP data, keyword rankings, and share of voice directly into the warehouse your company already invested in, next to the metrics that actually drive decisions.
Programmatic SEO Makes Per-keyword License Costs Untenable
Programmatic SEO changes keyword economics.
For example, a SaaS company tracking 2,000 commercial keywords can still operate comfortably inside traditional enterprise SEO software pricing models. A marketplace, ecommerce company, or a large publisher often cannot.
Large-scale programmatic SEO strategies regularly involve:
50,000 keywords
500,000 URLs
Millions of SERP observations
Continuous content generation pipelines
At that scale, traditional keyword licensing can become expensive quickly.
API-driven pipelines allow teams to:
Pull only the data they need
Cache responses
Build incremental refresh systems
Reduce redundant API calls
Control ingestion frequency
That flexibility matters financially. That’s why API-first providers like DataForSEO have gained traction, largely because engineering teams want predictable usage-based workflows instead of increasingly expensive suite licensing.
The Enterprise SEO API Surface, Mapped
The enterprise SEO API surface now spans rankings, keywords, backlinks, crawl telemetry, domain intelligence, AI Overview visibility, and technical site monitoring.
Most enterprises combine multiple providers because no single vendor dominates every category equally.
The right architecture depends on data freshness requirements, integration complexity, warehouse strategy, and whether the organization prioritizes operational automation or executive reporting.
Below is a practical breakdown of the major API categories enterprises use today.
API Category | Primary Use Case | Data Freshness | Geographic Coverage | Pricing Model | Integration Effort |
|---|---|---|---|---|---|
SERP APIs | Rankings, AI Overviews, SERP features | Real-time to daily | Global, multi-locale | Per usage/credits | Low — REST, JSON response |
Backlink APIs | Link graph analysis | Daily/weekly | Global | Per request/subscription | Low to medium |
Keyword APIs | Search volume and clustering | Weekly/monthly | Global | Usage/credits | Low |
Domain APIs | Authority and traffic estimation | Daily/weekly | Global | Subscription or per call | Low |
Crawl + GSC APIs | Technical SEO and first-party data | On-demand to daily | First-party | Mostly free/usage-based | Medium-high |
SERP APIs
SERP APIs power enterprise rank tracking, AI Overview monitoring, SERP feature monitoring, competitor visibility tracking, and display live search engine results data by geography and device.
Leading providers include:
DataForSEO: Offers SERP feature coverage and competitive batch pricing at enterprise data volumes
SerpApi: Widely used for ease of integration and solid documentation, though it is better suited for lower-volume use cases than enterprise-scale daily pulls.
Bishopi: Focuses on combining SERP intelligence with broader SEO and domain data under a unified API surface. This is useful when you need to know not just where you rank, but whether an AI Overview is suppressing your click-through rate on that query.
Backlink APIs
Backlink APIs expose the link graph, including referring domains, anchor text distribution, domain authority of linking pages, and lost or gained links. For enterprise link teams, the valuable signal is the delta, which links appeared or disappeared since the last pull.
Major backlink APIs include:
Ahrefs API: One of the industry’s strongest backlink indexes, particularly for enterprise competitive research, though its enterprise API pricing can be costly.
Majestic: Worth considering for trust flow and topical trust flow metrics if link quality analysis is a priority. It maintains one of the deeper historical indexes in the market.
Bishopi backlinks API: Covers referring domains, trust flow, citation flow, and toxic link detection in a single endpoint.
The right provider depends heavily on whether the enterprise prioritizes:
Freshness
Historical depth
Pricing efficiency
Warehouse-native ingestion
Keyword APIs
Keyword APIs return search volume, difficulty scores, intent classification, CPC, and SERP-level clustering data. Enterprise keyword tracking workflows typically pull this data in batch at once, to build opportunity scores and content brief queues against a target schema.
Key vendors include:
DataForSEO: Offers broad keyword data coverage across markets and is frequently used for large-scale volume lookups.
Semrush API: Offers strong intent classification and extensive keyword databases, though it sits at a premium price point compared to consumption-based alternatives.
Bishopi Keyword API: Covers volume, keyword difficulty, and SERP analysis with batch endpoint support.
These APIs are a foundational infrastructure for enterprises running programmatic SEO initiatives. Instead of manually researching terms, they enable teams to automate:
Opportunity scoring
Intent mapping
Cluster generation
Brief creation
Content prioritization
This matters particularly for enterprise keyword tracking pipelines operating at large scale.
Domain and Site APIs
Domain name APIs provide broader competitive intelligence, including:
Authority metrics
Traffic estimates
Tech stack identification
Domain history
Sales data
Ownership insights
They are most useful in multi-property monitoring, including tracking hundreds of client or competitor domains at once without opening a UI. This is also the right layer for crawl budget analysis: knowing a domain's crawl efficiency before you start building content programs.
Common providers include:
Similarweb’s API. The reference for traffic estimates and referral source breakdowns, though it prices accordingly for enterprise access.
Bishopi domain tools: Reveal domain authority, page authority, spam scores, trust flow, and traffic cost estimates programmatically. They are useful for SEO ops teams and domain investors monitoring large portfolios. These tools combine traditional SEO metrics with proprietary domain intelligence and valuation datasets
Crawl and GSC APIs
Your own site data is the one layer that no third-party data provider can fully substitute. It is critical because it reflects actual site behavior rather than third-party estimation.
Key systems include:
Google Search Console API: Free, rate-limited, and gives you 16 months of impression, click, position, and device data queryable by page and query.
Screaming Frog: Supports scheduled crawls via CLI that feed directly into your pipeline for ongoing technical site audits.
Botify API: Leads on log file analysis features, especially for large-scale publishers.
These APIs support:
Crawl budget analysis
Log file analysis
Indexation monitoring
Core Web Vitals analysis
Technical SEO workflows
Unlike external APIs, this layer gives you direct operational visibility into your own infrastructure.
Should You Build, Buy, or Blend?
Find the Best Enterprise SEO Solution.
Most enterprise teams don't need to choose between a pure API stack and a full suite. The right architecture depends on where your team's leverage sits.
Engineering capacity, BI maturity, and keyword volume are the three factors that determine which archetype fits. Three models govern how enterprises approach this:
Pure API Stack
This model works best for teams with strong engineering capacity and BI-first cultures, including mid-market SaaS companies, marketplaces, programmatic publishers, and engineering-heavy organizations.
They have already invested in a data warehouse and have a data engineer who can build and maintain ingestion pipelines. Their SEO reporting lives in Looker next to revenue data. Every dollar goes to data, not to UI seats they don't use.
This is often where the enterprise SEO conversation starts for engineering-led organizations.
Advantages:
Full data ownership
Flexible schema design
Lower marginal scaling costs
Easier cross-functional reporting
Better support for programmatic SEO
Tradeoffs:
Requires engineering support
Needs pipeline maintenance
Demands ETL expertise
Monitoring becomes your responsibility
This model often delivers the best economics once keyword counts exceed roughly 50,000 tracked terms.
Hybrid Stack
A suite for executive reporting and board-level visibility dashboards, with APIs for everything operational, including rank tracking pipelines, anomaly alerts, and content brief automation. This is where most enterprises actually land.
The suite provides a defensible single source of truth for stakeholders who want a clean dashboard without SQL access; the APIs power the workflows engineers actually build. The two layers are not in conflict but serve different audiences.
Suite-Led Model
This model works for:
Small SEO teams with no dedicated engineering allocation
Limited engineering support
Lower keyword volumes
Traditional reporting structures
Here, the suite wins because the UI is the workflow. There is no pipeline to maintain, and the cost of the API alternative is measured in engineering hours rather than dollars.
Many enterprise suites are themselves built on top of API providers like DataForSEO; the API stack approach simply removes the markup layer.
For teams in this archetype, the API conversation starts when they hire their first data engineer.
Advantages:
Faster onboarding
Less maintenance
Unified support
Easier stakeholder adoption
Tradeoffs:
Less flexibility
More expensive scaling
Limited workflow automation
Restricted warehouse integration
Here is a worked cost example with 10,000 keywords tracked daily for one year:
Let’s use a defensible scenario.
Enterprise suite (BrightEdge, mid-tier): BrightEdge contracts for mid-market deployments typically run $30,000–$150,000 per year. For a 10,000-keyword program, I’d estimate a reasonable mid-point of $48,000/year. This includes the platform, reporting UI, and support. It does not include implementation time (typically 1–2 months of internal resources) or the cost of data staying locked inside the platform's own export formats.
API stack with Bishopi: Bishopi's Professional plan provides 15,000 credits/month at $129/month (billed annually at $1,236/year). At approximately $0.0069 per credit, 10,000 daily SERP lookups at full enterprise volume fall into the Enterprise tier at $249/month (35,000+ credits). A custom volume arrangement for 10,000 keywords tracked daily typically runs $3,000–$6,000/year in API spend.
Engineering overhead: A data engineer spending 40 hours to build and 2 hours/week to maintain an ingestion pipeline, at a blended rate of $120/hour, costs approximately $17,280 in year one (build + 52 weeks of maintenance).
Year 1 | Year 2+ | |
Enterprise suite (mid estimate) | $48,000 | $48,000 |
Bishopi API + engineering | $18,000–$20,000 | $15,000–$17,000 |
Saving | $28,000–$30,000 | $31,000–$33,000 |
Important caveat: Suite pricing is negotiable and highly variable by contract. These figures use publicly reported benchmarks, not guarantees. Run the numbers for your specific keyword volume and contract terms. The breakeven point sits well below year one if you already have engineering capacity in place.
What do Enterprise SEO Workflows Look Like as API Pipelines?
An SEO API only creates value when it is wired into a repeatable workflow. Each pipeline below follows a consistent structure, so your engineering team can implement them without reinventing the pattern each time.
Together, they cover the operational core of enterprise SEO analytics: technical health, opportunity discovery, content production, rank tracking, and executive reporting.
Workflow 1 — Continuous Technical Audit
Trigger: A scheduled cron job fires nightly at 02:00 UTC, outside peak traffic hours, so crawl activity does not inflate server latency metrics.
API calls: Screaming Frog CLI crawl exports (or Botify API for JavaScript-heavy sites requiring log file analysis) pull the structural signals your team actually fixes, including broken internal links, redirect chains, missing or duplicate meta titles, missing canonical tags, and Core Web Vitals proxy metrics from response headers.
These run in parallel with Bishopi domain API calls for domain-level authority signals across your full property portfolio. The Google Search Console API pulls the previous day's impression and indexation data to surface any pages that stopped receiving crawl budget allocation.
Transform: A dbt model running in BigQuery or Snowflake joins the crawl export with GSC performance data on a page-URL key. The model calculates a severity score per issue: issue type weight (broken links score higher than missing meta descriptions) multiplied by the page's revenue contribution (pulled from a CRM join) and divided by current ranking position. This gives you a triage-ready ranked list rather than a flat crawl dump.
Destination:A Looker tile surfaces the top-10 severity-scored issues on the SEO ops dashboard, refreshed each morning. Any item crossing a severity threshold of 7 or above automatically generates a Jira ticket via the Jira REST API.
The ticket body contains the affected URL, issue type, severity score, the keyword cluster it belongs to, and a direct GSC link, everything the engineer needs to act without opening a separate tool.
Human action:The SEO engineer assigned to technical ops opens the Jira board each morning and works down the auto-generated queue. Because the ingestion pipeline handles schema-level latency between crawl and ticket, the average time from issue detection to ticket creation is under 30 minutes.
No manual report export, no spreadsheet handoff. For critical issues like a site-wide canonical tag regression, for example, the severity threshold triggers a PagerDuty page in addition to the Jira ticket.
Workflow 2 — Keyword Opportunity Discovery
Trigger: A weekly batch pull fires every Monday at 06:00 UTC, populating the opportunity queue in time for Tuesday planning sessions.
API calls: The Keyword API receives a batch request containing the seed keyword list, derived from your content taxonomy, competitive analysis, and site search data. The API returns search volume, keyword difficulty, CPC, and intent classification for every term in the batch.
For all terms clearing a minimum volume and maximum difficulty threshold, a second SERP API call fetches the current top-20 results: ranking URLs, SERP features present, AI Overview presence flag, and the content types dominating the result set.
Transform:The warehouse calculates an opportunity score per keyword: (monthly search volume × (1 − keyword difficulty)) adjusted downward by a factor proportional to AI Overview presence on that query, because AI Overview queries carry lower CTR expectations.
A CMS inventory join then filters out terms that already have a ranking page within the top 20. The remaining terms represent genuine content gaps, ranked by opportunity score.
Destination:The gap list feeds a content brief queue table in the warehouse, sortable by opportunity score, content type, and target funnel stage. A Looker dashboard surfaces the top 50 gaps at any given time. Keyword tracking at this level ensures every gap has a data-backed priority score.
Human action:A content strategist reviews the queue each Tuesday and makes three decisions per item: assign to a writer, pull into the content calendar with a target publish date, or flag for further strategic review. The SERP data is already in the brief. No separate competitive research step is required downstream.
Workflow 3 — Content Brief Production
Operationalizing SERP intelligence into scalable content creation.
Trigger: A brief status change in the CMS from 'queued' to 'assigned' fires a webhook that kicks off the brief enrichment pipeline.
API calls:The SERP API fetches the full top-10 for the target keyword at the moment of assignment. Not cached data from the weekly batch pull, because SERP volatility means a two-day-old snapshot can already be stale.
The response includes each ranking URL, page title, estimated word count, SERP features captured, and AI Overview content, where present. A second keyword API call pulls the semantically related terms, PAA questions, and related search clusters for the target query, the raw material for the brief's recommended heading structure.
Transform: A brief template in the CMS auto-populates with: primary keyword and target URL, secondary keyword cluster, current SERP feature landscape, summary of what the top-3 ranking pages cover (pulled from SERP snippet data), recommended H2 structure based on PAA patterns and top-ranking pages, the AI Overview content if one exists (so the writer understands what Google is already surfacing), target word count range, and the SME review SLA deadline.
Destination:The populated brief attaches to the CMS draft item and appears in the assigned writer's queue. The writer opens a structured document with a competitive context already embedded.
Human action: The writer and subject-matter expert review the brief together. They refine the angle, confirm the target audience, and make editorial judgements about what the top-ranking pages miss. The data layer handles the research; the human layer handles the judgement. Once approved, the brief moves to 'in production' and the publish SLA clock starts.
Workflow 4 — Enterprise Rank Tracking and Anomaly Response
This is the enterprise rank tracking workflow, the operational spine of real-time SEO visibility. It turns daily SERP API data into actionable alerts before anyone has opened a dashboard.
Trigger: A daily cron job fires at 07:00 UTC. For high-priority keyword clusters, a secondary cron fires at 13:00 UTC to catch intraday SERP volatility during peak crawl windows.
API calls:A SERP API like the one offered by Bishopi pulls current rankings for the full tracked keyword set using the Google SERP API endpoint, with device type and geo parameters matching each keyword's target market.
Critically, the JSON response includes an AI Overview presence flag and, where the Overview is detected, the list of cited domains. This means each daily pull answers two questions simultaneously: where do we rank, and are we being displaced by an AI Overview on this query? Keyword ranking data lands in the warehouse raw schema within minutes of the cron trigger.
Transform: The warehouse compares each keyword's current position against a 7-day rolling average. The anomaly detection model fires on three conditions: any tracked keyword drops more than 5 positions in a single 24-hour window; an AI Overview appears on a query where the site previously ranked in positions 1–3 (a CTR impact signal regardless of rank movement); or a new competitor URL enters the top 3 for a keyword in the high-priority cluster.
Each condition has a configurable threshold per keyword tier. High-value commercial queries trigger alerts at lower sensitivity than informational long-tail terms.
Destination:A Slack webhook posts the alert to #seo-alerts within seconds of the anomaly being detected in the warehouse. The message contains: keyword, previous position, current position, movement direction, affected URL, and a deep link to the Looker tile for that keyword cluster. For keywords in the critical tier, a parallel PagerDuty alert fires and routes to the on-call SEO engineer's phone.
Human action: The on-call engineer opens the runbook pinned to #seo-alerts.
Step one is always a GSC API verification. Confirm the position change is real and not a data artefact.
Step two is a crawl status check on the affected URL via Screaming Frog CLI.
Step three is escalation to engineering if a technical cause is identified (could be a canonical tag change, a robots.txt update, or a redirect regression). For AI Overview appearances on high-CTR queries, the runbook triggers a Linear task to review the content against what the Overview is surfacing, and assess whether a schema markup update or content restructure would improve citation chances.
Workflow 5 — Reporting and Pipeline Attribution
The final workflow connects SEO to revenue outcomes.
Trigger:A weekly aggregation dbt job runs every Sunday at 22:00 UTC, so the full week's data is ready in Looker before the Head of SEO's Monday morning review.
API calls: No new external API calls fire at this stage. All data is already in the warehouse from the week's operational workflows. The only additional data pull is a CRM join: a nightly Salesforce or HubSpot sync maps organic session UTM data to open pipeline opportunities using first-touch and last-touch attribution models, written as a dbt model that refreshes with each CRM sync.
Transform: The weekly DBT run aggregates five reporting dimensions:
Share of voice by keyword cluster (your impressions divided by total estimated impressions, trended week-over-week)
AI Overview citation rate across the tracked keyword set; organic traffic contribution segmented by content tier (top-of-funnel informational vs. bottom-of-funnel commercial)
backlink velocity (new referring domains gained vs. lost over the trailing 30 days from the Backlink API)
SEO-attributed pipeline contribution in dollars, sourced from the CRM join.
Each dimension feeds a named Looker tile with a target benchmark and a week-over-week delta indicator.
Destination: The executive Looker dashboard refreshes automatically. The Looker API generates a weekly PDF export, branded, single-page, and attaches it to an automated email sent to SEO leadership, the VP of Marketing, and the CMO.
A separate Slack message posts the week's headline numbers to #seo-reporting. The CRM field 'SEO Pipeline Contribution (Last 30 Days)' updates automatically on every account where organic was a touchpoint.
Human action:The Head of SEO reviews the Looker dashboard on Monday morning and writes the weekly narrative, a 200-word Slack post in #seo-reporting that contextualises the numbers, flags anomalies the automated system caught, and sets the team's top three priorities for the week. The data is already compiled and validated. The human adds interpretation and direction, which is the only part that a pipeline cannot do.
A Reference Architecture
A modern enterprise SEO architecture combines APIs, ingestion pipelines, cloud warehouses, transformation layers, BI tools, and operational automation into one connected system. The goal is not simply reporting but operational responsiveness — detecting ranking changes, technical regressions, and AI Overview shifts quickly enough to trigger action across engineering, content, and analytics teams.
Here is a practical vendor-flexible architecture covering:
Data Sources → Ingestion → Warehouse → Transform + BI → Alerting → Ticketing
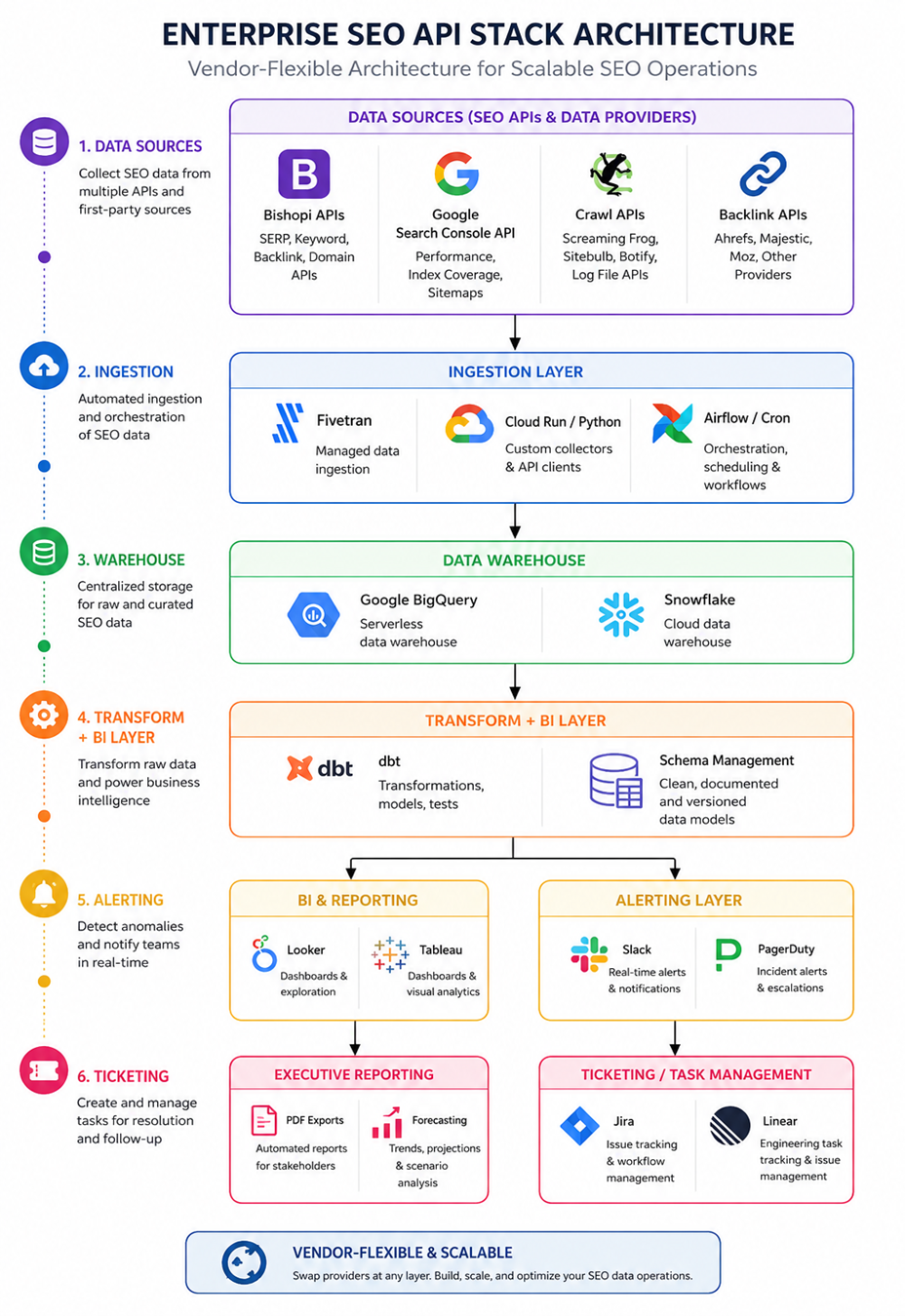
This architecture intentionally remains vendor-flexible.
Bishopi naturally fits in the API layer because it combines SERP APIs, keyword APIs, backlink APIs, and domain intelligence inside a unified interface. The surrounding infrastructure remains interchangeable.
There are a few trade-offs to note here:
Custom Python ingestion on Cloud Rungives you full control over schema, rate limit handling, and cost, but requires a data engineer to write, test, and maintain the pipeline.
Expect 30–40 hours to build it properly, including error handling, webhook retry logic, and the initial schema design.
Ongoing maintenance runs roughly 2 hours per week for schema changes, API version updates, and latency monitoring. The pipeline is yours: you own the behaviour and the debugging.
Fivetran-managed ingestion removes engineering toil entirely. Connectors handle schema drift, rate limits, batch endpoint pagination, and error retries automatically. The cost premium is real, approximately $500–$2,000+/month at enterprise data volumes, but so is the time savings.
For teams without a dedicated data engineer, Fivetran often pays for itself within the first quarter of avoided debugging time.
Enterprise SEO Analytics Across Four Dimensions
A well-instrumented SEO API stack should report across four SEO API metrics: Visibility, demand, trust, and AI visibility. Each maps directly to one or more API data sources in the stack, and each surfaces in a named tile in your tracking dashboard.
Together, they give stakeholders a complete view of SEO health without requiring access to the raw data layer.
Visibility: Measures your share of the SERP — positions, share of voice by keyword cluster, and SERP feature capture rate. The SERP API supplies this daily. The key metric is share of voice, which is your clicks divided by total estimated SERP clicks, by keyword cluster, trended weekly. A declining position with a stable share of voice is a different signal than a declining position with a declining share of voice.
Demand: Measures the total addressable search market, keyword volume trends, SERP clustering, and intent distribution across your tracked set. The Keyword API supplies this. Demand data tells you whether a position drop matters: losing rank on a keyword in a declining-volume cluster is a different problem than losing it on a keyword with 40% YoY volume growth.
Trust: Measures the authority signals that predict sustainable ranking, domain authority, backlink profile quality, referring domain growth rate, and toxic link exposure. The Backlink checker API and SEO data API supply this dimension. Trust metrics move slowly; a 30-day rolling window is usually sufficient for the reporting layer, with a 7-day alert threshold for sudden referring domain loss.
AI Visibility: This is genuinely an API-shaped problem. Capturing whether your pages appear inside AI Overviews across thousands of queries and tracking that over time is impractical through any manual process or per-seat tool.
A SERP API that exposes AI Overview presence in its JSON response turns this into a simple daily aggregation: how many of your tracked queries show an AI Overview, and how many of those cite your domain?
This metric is becoming as foundational as traditional rank position for enterprise SEO teams in 2026, and it cannot be monitored at scale without a programmatic data layer.
Frequently Asked Questions
Can I replace a suite like BrightEdge or Conductor with APIs?
You can replace most of what a suite does with an API stack, but not all of it. The gap matters depending on your team. APIs give you better data pipelines, lower cost at scale, and full control over where data goes. What you give up is the managed UI, the customer success team, and pre-built executive reporting.
Most enterprise teams land on a hybrid: APIs for operational workflows, Looker dashboards built on warehouse data for stakeholders. If your team has a data engineer and an existing warehouse, replacing the operational core of a suite is achievable in 4–8 weeks.
What does an SEO API stack cost compared to enterprise suite licensing?
The cost gap is significant at scale. Enterprise SEO suites like BrightEdge run from $36,000 to $150,000 per year at reported pricing ranges, with the median contract closer to $50,000 for mid-market deployments.
An API-based stack like Bishopi Enterprise at $249+/month plus data warehouse costs and engineering overhead typically runs $15,000–$20,000 in year one, including pipeline build time, dropping to $12,000–$17,000/year thereafter.
Above 20,000–30,000 keywords tracked daily, the API stack almost always wins on cost. Below that volume, the suite may still win on total effort if your team has no data engineer allocated.
How do you track AI Overviews and SGE citations via API?
SERP APIs that expose AI Overview presence return a structured flag and often the cited URLs, in the JSON response alongside standard organic ranking data. With a SERP API, each daily pull for a tracked keyword returns whether an AI Overview appeared and, where detectable, which domain the Overview cited.
Store this in your warehouse alongside position data, then aggregate daily: AI Overview appearance rate by keyword cluster, your citation rate across the tracked set, and the CTR delta between queries with and without AI Overview presence.
This gives you a share-of-AI-visibility metric that does not exist in any suite's standard reporting — and it updates daily because the AI Overview landscape shifts fast.
Conclusion
The build-vs-buy question in enterprise SEO is really a question of where your team's leverage sits. Teams with engineering capacity and an existing data infrastructure get more value from APIs than from suites; lower cost, better data integration, and actionable insights that actually reach the systems where work happens. Teams without engineering allocation get more from suites, because the UI is the workflow.
Ready to explore an API-first approach? Start your 7-day free trial here.
Originally published at: bishopi.io
Get updated with all the news, update and upcoming features.